Fast Web Scraping with Bs4 and httpx

As Data professionals(Data Scientists, Data Engineers, etc.) Our core mandate is to find, clean, analyze and extract meaningful insight from data for business purposes.
This is not always easy especially when it comes to curating data for a project. Even though there is a huge influx of data out there, it is not often readily available. This requires that we go and get data for such projects. One important source of data for a project is the internet. Yes, there is a huge amount of data available on the internet waiting to be extracted and used to influence data-driven decision-making.
In this article we will look at web scraping, tools of the trade, challenges of web scraping and most importantly, look at `async` web scraping with `Beautiful soup` and `httpx`. Let start with the definition of web scraping.
What is Web Scraping?
Web Scraping(also data scraping or web data extraction) is the automatic process of collecting data from a website for analysis.
Why do it?
Web scraping offers a unique opportunity to data professionals to collect data that is otherwise impossible to access.
It is the fastest way to data for your data projects.
For instance, most company have websites with a lot of content that is not available through an API to outsiders. In order for others to access these data, they will need to scrape it.
Web Scraping offers a cost-effective way to access that data that might require an expensive subscription to get.
Another huge advantage of web scraping is lead generation. Through web scraping you can generate a large dataset of potential customers for your business. This will significantly cut down cost of finding potential customers through marketing.
Challenges of Web Scraping
Even though web scraping offers an easy way to data, it comes with some challenges. They include the following:
1. You cannot scrape all websites: Even though it is not illegal to scrape websites, most websites mask or prevents users from accessing some content on their websites. In order to be sure if a website allows users to access some content on their websites, check the `robots.txt` file. This file will contain what is allowed and disallowed on the website.
2. Web scraping is extremely volatile: What is allowed on a website or worked for you today may change tomorrow. The structure, style or behavior of a website is determined by the owner, hence subject to change without notice.
3. Internet access: This may not be a problem for some people, but it is for others. For example, people living in areas with poor internet connectivity, scraping a website may take forever especially when the data is very large. This is because scraping a website requires sending requests to the server(of the website). Slow internet connectivity can also lead to incomplete results when scraping a website.
Tooling
If you are in the Python ecosystem, then you know that `requests`, `beautiful soup`, `selenium` and `scrapy` as the most popular web scraping tools available. These tools though, have their strengths and weakness. For instance, `scrapy` enable you to build advanced web crawlers and is fast. It is however, a little too large for small projects. `Beautiful soup` is the main tool for small scale to medium scale web scraping in Python. It is not as fast as `scrapy` but get the job done just fine. This however, becomes a challenge when scraping multiple pages on a website, especially when the data is very large.
In order to scrape data with `bs4(beautiful soup)`, you first need to make a request to the server for a resource. This is often done with the `requests` library, which is synchronous.
It is often a challenge if the request is synchronous. That means that it is slow because you have to get the data from the server bit by bit and in a sequential order.
As a result, this can take forever to get a decent response from the server especially if your internet connection is slow. It also results in incomplete response if any.
`Async` Web Scraping
To solve this problem, you need to do what is called `async scraping`. The concept is simple; instead of waiting for response when you send a request, you can instead send multiple requests at the same time. While a request is awaiting a response, a new request can be sent at the same time.
To demonstrate this concept, let’s scrape multiple pages of bestsellers from `https://www.bookdepository.com/` website.
We will be using Google Colab for our demo. Make sure to change runtime to `gpu` or `tpu` under the `view` then `notebook info` section.
In the new notebook, install the following:
!pip install httpx bs4 pandasWe used the command above to install the packages we will need for the job. `httpx` will be our `async` client for getting our web resources, `bs4` will be used for parsing our content and getting resources from the page and `pandas` will be used to manipulate our data.
We will start by getting the authors of the books on the website. We will scrape all the pages.
# get the authors asyncpage = 1authors = []while page != 35: async with httpx.AsyncClient() as client: url = f”https://www.bookdepository.com/bestsellers?page={page}" response = await client.get(url) html = response.content soup = bs(html, “lxml”) for p in soup.find_all(“p”, class_=”author”): authors.append(p.get_text(strip=True)) page = page + 1
Notice that we first created 2 variables; `page` which will keep track of the pages on the website while `authors` will hold our data. We then used a `while loop` to traverse our pages and get the data while our page is less than the total of 35(There are 34 pages on the website). I know this because I used the `chrome devtools` to inspect the `pagination` on the page.
Within our loop, we use `httpx` to retrieve the pages asynchronously. We then substituted the page into the `url` in order to get them all(one at a time).
After that we passed our `HTML` content with `bs4` and the `lxml` parser because it’s fast.
Finally, we use `bs4` to get each author in our `p` element with the class of `author`. We also appended the data to our `authors` list.
Now when we check the length of the `authors` list, we will get the number `1020`.
NB: Google Colab will let you know that `await` keyword can only be used within an `async` function, but you can ignore this for now since it will not affect the results.
len(authors)We just need to do the same thing for the rest of variables we are interested in.
# get the titles asyncpage = 1titles = []while page != 35: async with httpx.AsyncClient() as client: url = f”https://www.bookdepository.com/bestsellers?page={page}" response = await client.get(url) html = response.content soup = bs(html, “lxml”) for p in soup.find_all(“h3”, class_=”title”): titles.append(p.get_text(strip=True)) page = page + 1
Then check the length of your variable list:
len(titles) # output 1020In order to get gather our data for further cleaning or analysis, we need to create a dataframe with `pandas`:
import pandas as pddf = pd.DataFrame(titles, columns=[“titles”])df[“author”] = pd.Series(authors)df
Let continue with even more variables like the price and format:
# get the prices asyncpage = 1prices = []while page != 35: async with httpx.AsyncClient() as client: url = f”https://www.bookdepository.com/bestsellers?page={page}" response = await client.get(url) html = response.content soup = bs(html, “lxml”) for p in soup.find_all(“span”, class_=”sale-price”): prices.append(p.get_text(strip=True)) page = page + 1
Notice that the only things changing is the variable names and the `HTML` and `CSS` elements we are using to get them in the page.
Now if we check the length:
len(prices) # 1018You will realize we miss 2 values for the price. We can fill these in later when we are cleaning our data.
Now let’s add price to our `dataframe`:
df[“prices”] = pd.Series(prices)Let’s confirm that we have 2 missing values in our result:
df.prices.isnull().sum() # output 2The tail of our `dataframe` should now look like the following:
df.tail()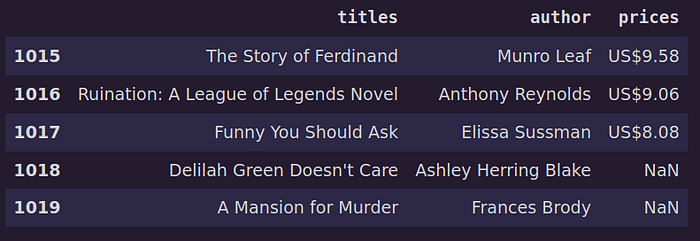
Finally, we let’s do the same for the format variable:
# get the format of the bookspage = 1formats = []while page != 35: async with httpx.AsyncClient() as client: url = f”https://www.bookdepository.com/bestsellers?page={page}" response = await client.get(url) html = response.content soup = bs(html, “lxml”) for p in soup.find_all(“p”, class_=”format”): formats.append(p.get_text(strip=True)) page = page + 1
Add it to our `dataframe` and check the data:
df[“format”] = pd.Series(formats) # add it to the dataframe
Now that we have our complete data, it might be wise to export to a `csv` file so that we can clean it later for our analysis.
df.to_csv(“bookdep_bestsellers.csv”) # export data for further cleaning and analysisConclusion
In this article, you learned about some of the challenges of web scraping and how to overcome them by scraping websites asynchronously using `bs4` and `httpx`. I hope this article helps you to make your web scraping faster using the concept and tools discussed here.
